

01
2025.07.18(Fri)
この記事の要約
NTTドコモビジネスの生成AI事業を担う3氏が、国産LLM「tsuzumi 2」の可能性と課題を語る。
法人向け生成AI活用を推進する北川氏は、CX・EX向上やセキュリティ分野での実装事例を紹介。吉田氏は、AIによる新たな与信判断を用いた中小企業向けローンサービスなど、データ活用による金融革新を説明した。R&D側の岩瀬氏は、tsuzumi 2が約300億パラメータという軽量設計で、日本語性能と機密データのオンプレミス運用に強みを持つ点を強調する。
一方で、クラウド型LLMに比べたコストや運用負荷は普及の課題とされた。ただし、専門特化型AIとしての小回りの良さや高いROIを生む用途、特許創出などトップラインに寄与する可能性も示される。生成AI活用を進めるにはトップダウンの導入や評価制度が有効で、今後はマルチモーダルやコンテキストエンジニアリングが次の注目領域になると展望された。
※この要約は生成AIをもとに作成しました。
目次
※前編「AIビジネスのネクストステップへ。馬渕邦美氏と考える、「専門特化型生成AI」のリアルと可能性」を読む
──部門は違えど、お三方ともNTTドコモビジネスで生成AIビジネスに関わっています。それぞれどのようなお仕事をされているのでしょうか?
北川公士(以下、北川):私はジェネレーティブAIタスクフォースという部に所属し、法人顧客に生成AIのソリューションを提供しています。生成AIを活用することで、CX(顧客体験)、EX(従業員体験)、CRX(サイバーレジリエンス・トランスフォーメーション)を向上させる仕事ですね。
例えば、AI SOC(サイバーセキュリティ・オペレーション・センター)を開発して、AIを使って24時間サイバー攻撃の検知・分析をするソリューションの提供や、AIがユーザーの要件を尋ねて案内までを担当することでCXとEXの満足度向上を両立させるプロダクト「ANCAR」のサービス提供などを手掛けています。

吉田徳太郎(以下、吉田):私はプラットフォームサービス本部に在籍し、主に中小企業のお客さまの課題を解決するプロダクトやサービスをお届けすることをミッションにしています。
最近では株式会社ドコモ・ファイナンスと連携し、与信をAIが支援する新しい仕組みのビジネスローンサービスを手掛けました。
──AIが与信を支援すると、どんなメリットがあるのでしょう?
吉田:より多くの与信材料を検証でき、正確なリスク判断をさらにスピーディにできるようになります。結果として、これまでの与信ならば資金調達できなかった企業でも借り入れできる可能性が高まります。
新たに与信に使える可能性がある材料のわかりやすい例のひとつが、支払い記録です。「長年毎月、遅れることなく支払いしているか否か」といったデータは、既存の金融機関では与信判断の対象になりませんでしたが、低リスクの企業と判断するデータのひとつとして有効になります。場合によっては、「資本力は豊富だが支払いにムラがある企業」などより与信が高いこともあり得ます。
弊社は膨大なデータを持っています。こうした広範囲で精緻なデータにAI技術を掛け合わせることで、ユーザーの資金サポート機会を増やせるわけです。

──まさに中小企業の経営者にとてもニーズが高そうです。一方、岩瀬さんはR&D系部門のイノベーションセンター所属ですが、「tsuzumi 2」の開発にも携わられているのでしょうか。
岩瀬義昌(以下、岩瀬):いえ、tsuzumi 2 はNTT株式会社が開発しています。NTTグループの研究所は基礎研究に近いものが多くありますが、事業会社の研究開発組織であるイノベーションセンターは、事業に比較的近い研究開発もしつつ、tsuzumi 2などの先進技術の事業活用を探る役割を担うチームですね。
ですので、生成AIに関しても、毎日マニアックな論文を読んでいるメンバーもいますが、北川さんや吉田さんなどのビジネスの現場に近い方々に「こんな技術つくったのだけど、どう?」「一緒にお客さまに実証実験の提案にいかない?」と声がけして、協働なども積極的に行っている感じです。

──tsuzumi 2は、生成AIビジネスのネクストトレンドとして注目を集める「専門特化型生成AI」においても要となるポテンシャルを備えたLLMです。改めてその特徴と注目を集める理由を教えてもらえますか?
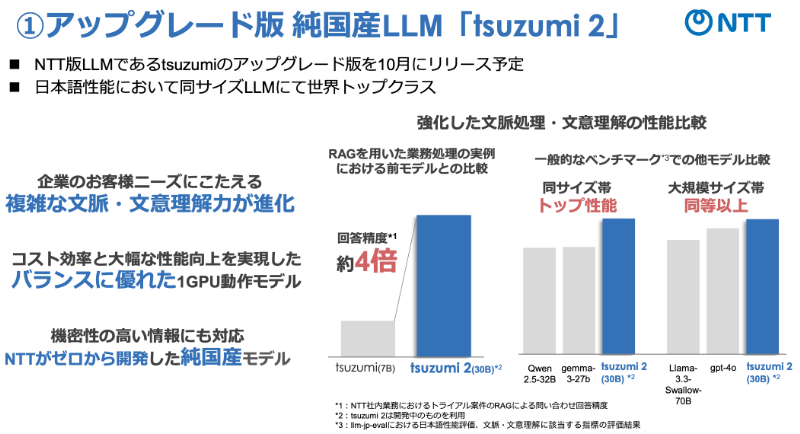
岩瀬:NTTは、日本語処理性能の高さと軽量さを兼ね備えた国産LLM「tsuzumi」を2024年3月にリリースしましたが、その次世代モデルとして2025年10月より提供を開始したのがtsuzumi 2になります。
もっとも大きな特徴は、パラメータ数(変数)が約300億であることです。LLMのパラメータ数は生成AIの推論能力に強い関連があります。例えば、GPTやGeminiといったビッグテックのLLMはパラメータ数が数兆にも及ぶことで高い予測精度を実現している、といわれています。
──tsuzumi 2の300億は見劣りしませんか?
岩瀬:パラメータ数だけで比較するとそうですね。一方で、パラメータ数が増えると、LLMを走らせて計算するためのGPUが大量に必要になるデメリットもあります。数兆となれば、1つのモデルを動かすだけで数十枚ものGPUが必要になることもあります。GPUは8枚搭載の筐体が1台増えると、だいたい大きな家が1軒建てられるくらいのコストがかかるのです。
前出のGPTやGeminiは、世界中のオープンデータを扱った高性能なGPUでの計算をクラウドサービスとして提供するビジネスモデルのため、その運用を行えるような設備投資も積極的にしています。
ただし、企業や自治体などが持つ機密性の高いクローズドデータを扱い、より限定的な用途で精度の高い出力を目指す専門特化型生成AIとして活用する場合、膨大なパラメータはオーバースペックになり得ます。パラメータ数は300億で十分、というケースは少なくありません。また、300億はGPUちょうど1つ分の計算容量だというのもポイントですね。
──なるほど。tsuzumi 2を使う際のハード面のコストは、1枚のGPUを用意するだけで済むわけですね。
岩瀬:その通りです。まして機密性が高いデータを学習させるとなれば、オンプレミス(自社施設内にサーバーを設置するスタイル)でセキュアに運用できることが重要になってきます。その点を踏まえれば、ビッグテックのLLMクラウドサービスよりも適した選択肢となり得るでしょう。
加えて、tsuzumi 2は私たちNTTグループの研究所が長年積み重ねてきた広く深い日本語研究の成果といえる「(学習に適した)もっともきれいな日本語」の学習データでつくりあげています。同じようにパラメータ数を300億に収めたLLM、あるいはSLM(小規模言語モデル)は数多くありますが、日本語を扱う上で、それらに負けないモデルとして開発してきたのが、tsuzumi 2です。
──前編でも話題になりましたが、ビッグテックのLLMはオープンデータからつくられていることもあり、現状では「LLMに学習された企業データはわずか1%しかない」という見方もあります。tsuzumi 2は、精緻で機密性の高い専門特化型生成AIとして、企業や自治体などが保有する機密性の高いデータの“ロックを解除する”ブレイクスルーになるということでしょうか?
岩瀬:そのポテンシャルは十分あると考えています。
──ビジネスの現場に近い目線で見ても、tsuzumi 2は多くの企業のニーズを満たすことになりますか?
北川:そうですね。サービス利用側の企業の目線でいうと、精度の高さや機密性もありますが、「国産である」ことへの期待がとても高いです。
tsuzumi 2をPoCとして採用いただいている顧客数社とのやり取りでも感じることですが、地政学や安全保障面のリスクが高まる昨今、自国で主権を持って開発・運用する「ソブリンAI」が強く求められています。特に、グローバルなビジネスを展開している、製造業の大企業や自治体などで、そういった意識の高まりをより実感します。
岩瀬:確かに、LLMが言語からつくられる以上、その言語を母国語とする国の思想や価値観が不可避に反映されてしまいます。歴史教育などでは特に顕著ですが、そうしたバイアスが、時として望ましくない回答を生成する直接的な要因になってしまいますからね。
北川:ただ一方で、tsuzumi2が普及するには、まだ課題を感じる面もあります。
──具体的には何でしょうか?
北川:やはりコスト面ですね。
岩瀬さんが述べられたように、GPUが1つで済む、という面では低コストです。ただ、それはあくまでオンプレミスを要件として考えた場合であって、クラウドサービスと比較するなら、ビッグテックのLLMとRAG(検索拡張生成=LLMが回答する際にデータベースを検索・参照するアーキテクチャ)の組み合わせの方が割安になってしまう。
さらに、tsuzumi 2をオンプレミスで運用するとなると、今後3や4へとバージョンアップする際、その都度ファインチューニングする必要が出てきます。しかしGPTやGeminiのようなクラウド型のLLMは、その必要がない。つまり、バージョンアップのコストにおいてもtsuzumiの方が割高になり得るわけです。

──とはいえ、オープンなLLM+RAGでは、tsuzumi 2(+RAG)よりも機密性が劣り、漏洩などのリスクがありますよね。
北川:ありますね。ただ、お客さまとコスト面の話を詰めていくと、「それならクラウド型のLLMとRAGの組み合わせでいいかな」「多少、機密性のところは目をつむるか」といった結論になりがちです。
岩瀬:いろいろな話がありますが、例えば某ビッグテックの生成AIは、ユーザーから1ドルの売上を得るごとに自社の利益を3ドルくらい溶かしている、といわれることもある。つまり、まずは使ってもらうことに舵を振り、戦略的にシェアの獲得を優先していると想定されます。一方で、tsuzumi 2はその方向では展開していません。
ファインチューニングに関しては、巨大なLLMであってもうまくいかないケースは少なくありません。その点、パラメータ数の少ないtsuzumi 2は小回りも利き、特定ドメインにおける性能のトップラインをむしろ磨いていけると考えています。tsuzumi 2のようなLLMは、専門特化型で使うと強いのです。
わかりやすい例でいうと、Gemini3は汎用性能がものすごく高いけれど、例えば3手詰め棋譜を読み込ませてみても、まったく解けなかったりするんですよ。汎用モデルは高度な数学の問題を解けますが、身の回りにある簡単な問いが意外と解けません。
吉田:それは衝撃的ですね。特定分野には弱いということですか。
岩瀬:ルールは知っているけれど解けない、といった状況になる。むしろ小さなCPUで動く将棋用のAIやアルゴリズムに負けちゃうわけです。
北川:それはいってみれば、「すべての業務に生成AIを使う必要はない」ということでもありますよね。生成AIの弱点は、何をするにも1から毎回推論する仕組みになっていること。だから出力結果が一定にならず、答えが1つしかないようなシーンでは使いづらい。それならばRPA(Robotic Process Automation)の方がずっと仕事ができますよね。
岩瀬:いわゆる自動化で十分だというケースもありますね。クラウド型のLLMか、専門特化型生成AIか、あるいは自動化か。用途に応じて最適解は変わってきそうです。

──生成AIの新しい可能性に目を向けると、いかがでしょうか? 省力化だけではなく、トップライン、売上に大きく影響したり、新たなビジネスモデルにつながったりするような用途が見えたら、また一段フェーズが変わりそうです。
北川:私たちのチームが手掛けている「特許」の領域は、そういった可能性もかなりあるかなと思いますね。
機密性が高い特許のアイディエーションのところからtsuzumi 2を使うのですが、するとそれまでは1,000件出すのが精一杯だったところが、1,100件ほどの特許を出せるようになりました。
製造業ならば、特許の数はそのまま競争力になりますから、トップラインの成長にもつながる。単に生産性を高めるだけじゃない領域にわかりやすく踏み込め、結果も出やすいですよね。
岩瀬:なるほど、面白いですね。個人的には、生成AIが一番輝いている領域はコーディングだと思います。これまで人間が書いていた以上のコードをAIが書くようになり、新しいアプリケーションも次々と生まれてき始めていますね。
吉田:コーディングに関しては、これまでまったくコードを書けなかった人でも、アイデア勝負でゲームやアプリをつくれるようになる、という点は大きいと思います。そうした人が増えれば、これまでなかった着想のクリエイティブが生まれる可能性は高まるでしょう。
私もスマホアプリをつくった経験はありませんでしたが、ChatGPTにいわれるままコピペしたら、愛猫が大活躍するアクションゲームをつくれましたからね(笑)。
──確かに。コーディングしていた人の仕事がなくなるというより、これまでコーディングをしたことがなかった人が、新たな力を発揮するともいえますよね。そこからイノベーションが生まれるかもしれません。
吉田:あとは、CTOやCFOといった「CxO」職を支援してくれるような働きを生成AIが担ってくれたらいいなと思っています。それこそ、社内の情報をtsuzumi 2で網羅して、最適解を吐き出すようなスタイルで。
生成AIに限った話ではありませんが、企業に新しいテクノロジーを提案する際には、必ずROI(投資利益率)の話になります。AIを業務に使いたいという思いは、すでに多くの経営者が持っている。ただ、ROIの面で見ると、総論賛成・各論反対で止まってしまうケースを多く経験しました。
そう考えると、一般の現場業務を肩代わりするよりも、CxOのように各専門領域を横断して総合的な判断を担う役職こそ、AIが手助けしたほうがいいのではないかと思うのです。AI導入ありきでの最適解を出してくれますし、ROIもわかりやすく改善するはずですからね。

──そうした圧倒的に高いROIの実現や、新たな付加価値を生み出すようなビジネスの創出につながってくれば、生成AIはさらに企業に浸透していきそうですね。
北川:裏を返すと、事業に生成AIをしっかりと実装しているか否かで大きな差が出てくることにもなると思いますよ。いまから実証を進めている企業と、各論反対で止まっている企業とでは、どこかで大きな差がつくのかもしれません。
岩瀬:インターネットの歴史と似ていますよね。得体の知れないものとして、ネットの導入が遅かった企業や産業は衰退していった。逆に、GoogleやAmazonのように、そこに早くからベットして投資していた企業から次世代を担うビッグビジネスが生まれた……。そういう歴史が繰り返されるように、急速な進化を遂げる生成AIネイティブ企業がこれから間違いなく生まれるでしょうね。
──同じ轍をふまないため、「各論反対」で止まりがちな企業が生成AIソリューションの社内実装を進めるための良い策はありますか?
吉田:トップダウンで強制力を働かせることも選択肢かもしれません。「この業務は生成AIを必ず使うように」「ここまでは生成AIで業務を遂行しなければならない」といった具合に。リモートワークがコロナ禍で一気に広まったように、号令がかかればガラリと変わる面がある気がします。
岩瀬:確かに。海外のビッグテック企業では、生成AIの活用度を人事評価に入れはじめたところもありますからね。強制力というか、インセンティブを用意すると変わるかもしれません。
吉田:とにかく触ってないと「もしかしたらこんなことに使えるかも」といったアイデアも出てこないと思います。逆にいえば、とにかく触って使ってみたら、着想が刺激される可能性は高いです。これは我々NTTグループにとっても必要な策かもしれません。
北川:どこの会社でも、プライベートを含めれば、生成AIを使ったことがある人がほとんどだと思います。ただ、それをそのまま仕事に持ち込むのはまずいのではないか、何かしら不具合や不利益が生じるのではないかと感じたまま、恐る恐る使っている人が多い。
だから、トップダウンで「必ず使うように」というのもひとつですし、あるいは「社内の書類や資料は、生成AIでつくったものでOK」と全社にアナウンスする程度でも、効果は大きいかなと思いますね。レギュレーションに組み込んで、「使うのが正」という環境をつくっていった方がいいのではないでしょうか。
──足踏みしているうちに、専門特化型生成AIに変わるトレンドテクノロジーが出てくるかもしれません。特にAI周りはサイクルが早いですよね。皆さんが気になっているトピックはありますか?
北川:すでに散々いわれていますが、次はやはり「マルチモーダル」だと思います。テキストや画像だけでなく音声や温度、振動などあらゆるデータをセンシングして統合し、AI解析に活かす。あとはパーソナルデータの活用ですよね。
こうしてリッチなデータが使われ始めると、本当に人のように動くロボットが現れて、また世界が変わりますよね。同時に、セキュリティの重要度も比べものにならないほど上がるでしょう。
岩瀬:僕はいま少しずつ注目され始めている「コンテキストエンジニアリング」の重要性が増すと考えています。
AIはものすごく賢くなっていますが、正しい言葉を使っても、それだけでは必ずしもイメージ通りに働いてくれるわけではありません。その言葉がどのようなコンテキスト(文脈)を含んでいるのか、業務知識を含め、いわば言葉がまとう空気感や背景みたいなものまでをすべて汲み取って複合的に理解できれば、高い精度でイメージ通りの働き方をしてくれるはずです。一方で今のAIは、文脈を詰め込むほど混乱し、かえっておかしな挙動をしてしまうこともある。まだここにはのびしろがあるし、面白い領域だと思いますね。

──いずれ、マルチモーダルとコンテキストエンジニアリングが折り重なるポイントを迎えそうですね。表情から文脈を読み取れるようになったり、複雑な「空気」を察知できるようになったり。
吉田:そうしたあらゆるテクノロジーを使って、一人ひとりの生活が豊かになれば、それが正解だと思いますね。
私はワインが好きで、よくネットで買うのですが、AIが好みを把握して「吉田さんにオススメの1本」を薦めてくることがありました。それを頼んでみると確かに美味しい。専属のソムリエを頼むのはなかなか難しいですが、AIならそれができる。私も美味しい未知のワインに出会えて、ワインショップも売上や利益を上げて、常連を増やせる。
AIの進化で埋もれたニーズを掘り起こすことができれば、日本はもっと元気になり、景気ももっと良くなっていくはずです。コスト削減や効率化を推し進めるだけでなく、人間にとっての高付加価値を創出するような生成AI活用も模索していきたいですね。
北川:そういうのやりたいですね、確かに。
──新たなイノベーションにも期待しています。本日はありがとうございました。

OPEN HUB
THEME
Generative AI: The Game-Changer in Society
#生成AI




