

01
2024.04.20(Sat)
この記事の要約
2025年SXSWでも注目された「専門特化型生成AI」は、一般LLMが扱えない企業固有の知見を活用する仕組みで、ニーズが高まっています。
モルガン・スタンレーはLLMとRAGを組み合わせて金融ナレッジをAI活用し、効率化と顧客満足度向上を実現。とある製造業の企業では、特許DBをAI活用して新規特許創出に応用しました。
専門特化型生成AIは「LLM+RAG」と「DSLM(領域特化型生成AIモデル)」の2方式があり、一長一短。最近ではNTT「tsuzumi 2」など新たな有力SLMも登場しています。
国産開発はソブリンAIの観点からも重要で、日本の製造業や職人技術をAIに事業承継すれば、新たな価値創出や海外展開も期待されます。さらにAIエージェントの進化により製品開発の速度と品質は飛躍的に高まり、日本企業も触れて試し、未来を描きながら共創を進める姿勢が求められています。
※この要約は生成AIをもとに作成しました。
目次
――2025年3月に開催された「SXSW(サウス・バイ・サウスウエスト)」でも、今後3年の生成AIビジネスにおけるブレイクスルーとして「Domain Specificity(領域固有性)」がキーワードとして話題になるなど、「専門特化型生成AI」のニーズがグローバルに高まっているといわれています。そもそも専門特化型生成AIとはどんなものか、ニーズが高まる理由を踏まえて教えてもらえますか。
馬渕邦美氏(以下、馬渕氏):OpenAIの「GPT」やGoogleの「Gemini」、Anthropicの「Claude」など、LLM(大規模言語モデル)をビジネスに活用することが世界で当たり前になりつつあります。
さらに最近は、「AIエージェント」も一般的になってきました。単にユーザーの指示に応じるだけではなく、AIが自律的にタスクを計画し、実行していく。まさにエージェント(代理人)のような役割を果たす生成AIが、ビジネスの現場に浸透しつつあるのです。
もっとも、こうしたちまたの生成AIは、パブリックに公開されたオープンデータを学習しています。それゆえに極めて幅広くバラエティに富んだタスクを高い精度で実行できるわけですが、学習データには特定の企業や組織だけが持つ機密性・専門性の高いデータはほぼ含まれていません。
指摘されたSXSWのキーノートでも、IBMのCEOであるアービンド・クリシュナ氏が「LLMに学習された企業データはわずか1%程度に過ぎない」と発言していましたからね。

――99%はパブリックデータで、企業内のデータは既存の生成AIにはほぼ活用されていないわけですね。
馬渕氏:そうなのです。とても賢くタスクをこなしてくれる生成AIですが、知識の質としては「浅く広い状態」ともいえる。ビジネスの現場で培われ、企業や社員の中に蓄積する濃密な知見や専門性の高いナレッジは活かされていないままです。
裏を返すと、こうした企業や産業の中にロックされた付加価値の高いデータを生成AIに学習させることができれば、現場の業務により効果的に生成AIを活用できるのはあきらかです。こうした流れで今、専門特化型生成AIのニーズが高まっているのです。
――なるほど。改めて、専門特化型生成AIとはどのような仕組みなのでしょう?
馬渕氏:いくつかバリエーションがありますが、すでに普及が進んでいる仕組みを2つの事例で説明しましょう。
アメリカの金融最大手のひとつであるモルガン・スタンレーは、LLMが回答する際に外部データベースを検索・参照できる「RAG」という付加機能を活用し、GPTと同社の膨大な金融ナレッジを、秘匿性を担保して組み合わせることで、専門特化型生成AIとして活用しています。仕組みとしては、「LLM+RAG」というパターンですね。
モルガン・スタンレーが積み上げてきた10万件以上の専門的なドキュメントをRAGでデータ活用することで、金融商品の詳細な特徴や条件をすぐさま回答し、データにもとづいた市場動向や投資戦略のスピーディーな分析なども可能になりました。過去に活躍してきた素晴らしい金融パーソンたちの知見を効率的に引き出して、分析の最適化に活かしています。
同社のアドバイザーチームにおける導入率は98%で、検索時間の大幅な短縮ができたそうです。加えて、アドバイザーたちは、空いた時間を顧客との関係構築や丁寧な戦略提案にあてられます。
――効率化のみならず、顧客満足度を上げることにも寄与しているわけですね。
馬渕氏:まさにそこが専門特化型生成AIのメリットで、導入のインセンティブになる部分です。生成AIのビジネス活用といっても、現状は部分的な業務効率化にとどまっているケースも多く、経営層としてはそれだけでは導入コストをかけ続ける意義を見いだしにくい。しかし、売り上げ・利益のトップラインに影響する投資になるなら、話は変わってきますからね。
もうひとつの例としては、ある製造業の会社では、社内の特許データベースを学習させた独自の言語モデルをつくり、特許データをチャットベースで自在に引き出せる仕組みをつくりました。これは独自に専門特化型生成AIモデルを開発したパターンです。過去事例の検索・参照を効率化するだけではなく、新たなユースケースを考えるアイデア出しや壁打ちのツールとして使い、売り上げ・利益の向上に役立てています。
ただ、いずれの例も、現時点では社内利用として活用が進んでいる段階にあります。機密性の高い社内データを学習させた言語モデルの開発にはさまざまなハードルがあり、それをサービスとして外部に提供するとなればなおさらです。
ゆえに“どうすればロックを外せるか”が議論のテーマになっている、というのが現状ですが、移り変わりの早いグローバルな生成AIビジネスにおいては、そうした成功事例も3年以内には台頭してくるだろうと予見されているわけです。
――北川さんは、すでに企業の生成AI活用の現場に多く携わってこられていますが、日本国内でも似たような状況にあるのでしょうか?
北川公士(以下、北川):そうですね。日本においても、専門特化型生成AIが極めて可能性のある領域だという認識は広まりつつあると思います。現に我々も、すでに複数の企業から受注、あるいはご相談も受けています。
ただ、自社に最適な専門特化型生成AIを築き上げる方法論や、それをビジネスに活用して成果を上げるためのメソッドに関しては、まだまだ定まっていないなという実感もあります。
――専門特化型生成AIの方法論における課題とは?
北川:馬渕さんが述べられた2つの仕組みを深掘りしていくとわかりやすいのですが、まずそもそもの定義としては、専門特化型生成AIは「DSLM(Domain Specific Language Model:領域特化型言語モデル)」と呼ばれ、軽量なLLMを活用して独自に開発するモデルを指すことが多く、LLM+RAGによるものとは区別されています。
DSLMは、特定の企業や業界、あるいは用途に特化したデータを学習させて独自に開発する言語モデルです。GPTなどのビッグテックが開発するLLMでは、予測能力を決定する要素ともいえるパラメータ数(変数)が数千億~数兆に及ぶのに対して、数百万~十億前後と大幅に少なく構成されるケースも多く、単にSLM(Small Language Model)と呼ばれることもあります。
学習データを専門的な内容に絞っているため、コストに直結するモデルサイズが小さく済み、処理スピードも速くなります。さらに用途も限定されるため秘匿性を担保しやすく、オンプレミスなどのクローズドな環境で利用するのにも最適、というわけです。
ところが、実際にSLMを使って専門特化型生成AIを実装しようとすると、やや見劣りする実情もあります。

――LLM+RAGと比較して、見劣りする?
北川:そうです。自社のデータベースをRAGでLLMと組み合わせたものと比較すると、まだ満足な結果が出にくい。ユーザーに期待される「論理性が高く“それらしい”回答」のクオリティは、LLMの膨大なデータセットによって安定的に生み出される傾向が強く、端的にいえば、SLMを使ったDSLMのほうが見劣りしたアウトプットになりがちなのです。
そのため、現段階ではモルガン・スタンレーの例にあった通り、GPTやGeminiなどの既発のLLMとRAGの組み合わせによって専門特化型生成AIを形にしているケースが多いです。
もっとも、LLMはパラメータ数が膨大で、処理速度も遅くなる。コストパフォーマンスと秘匿性の高さはやはりSLMに軍配が上がります。ただ、SLMには「維持が大変」という側面もある。モデルアップデートのたびに再度学習させなくてはならず、同じ回答結果が出るとも限らない。その点、LLM+RAGであれば、LLMと専門特化データベースが分かれているため、むしろ加速度的なモデルのアップデートはそのまま性能向上として恩恵を受けやすいのです。
――DSLMにしてもLLM+RAGにしても、一長一短なのですね。
北川:馬渕さんも述べられていたように、専門特化型生成AIのニーズが高まる一方で、「ROI(投資対効果)は出せるのか?」と考えると、そのあたりが悩ましい状況にあるわけです。ただLLMもSLMも、開発のコストは今後大きく下がっていくことが見通されていて、企業はそのあたりの方向性も見定めながら、投資のタイミングを見極めているフェーズといえます。
――ブレイクスルーは何をきっかけに起こりそうでしょうか。
北川:DSLMに最適なパラメータ数を持つ新たなモデルサイズ帯のSLMが台頭しつつあります。
我々NTTグループでも、「tsuzumi」というパラメータ数が70億のSLMを開発し、2024年3月よりサービス提供してきました。ただ、専門特化型生成AIとしてのポテンシャルをフルに発揮させようとするには、ややパワー不足でした。
そこで2025年10月、アップデート版の「tsuzumi 2」を公開しました。これはAlibabaの「Qwen」やGoogleが公開したSLM「Gemma」などと同等の約300億のパラメータサイズで、処理パワーも速度も満足なレベルを出しつつ、論理性の高さなどにおいても十分なクオリティを発揮し、かつクローズド環境でも動かせるサイズなので、専門特化型生成AIにおいても最適解として提案できると自負しています。
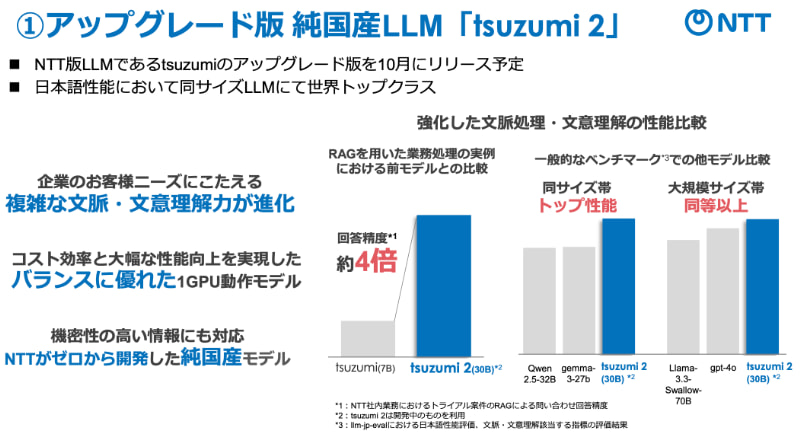
――DSLMにふさわしいSLMがすでに生まれ始めているわけですね。
馬渕氏:とても興味深いですね。tsuzumi 2は、オープンソース的なSLMとして企業などの組織向けにチューニングして展開していくソリューションだけでなく、「コストパフォーマンスに優れた軽量LLM」としてグローバルに広げていく戦略もとれそうです。どのような展開を考えているのでしょうか?
北川:両方の戦略を進めていますが、いずれにせよ根底にあるのは、自国のデータや技術基盤、価値観にもとづいて、自国で主権を持って開発・運用する「ソブリンAI」の発想だと考えています。
馬渕氏:非常に重要な観点ですね。生成AIの技術競争に関しては、先行するアメリカを中心としたビッグテックが、桁違いの投資とともに先行者優位を築いています。日本がその最前線に追いつこうとするのは、もはやリアリティがない。
一方で、だからこそ、国産AIをつくる必要性も高まっています。いくら利便性が高くても、他国発のAIに依存しすぎると、自国のデータを他国に提供し続ける構造が固定化されていくわけで、国家安全保障や地政学的なリスクヘッジができません。そうした防衛面での必要性はもちろんのこと、他国への資本流出を食い止め経済的な主権を得るためにも、日本独自のインフラとネットワークの中で、国産AI技術を確立し、運用していくべきだと思います。

北川:各国首脳の考え方ひとつで国策が大きく転換し、その余波によって社会に大きな混乱をきたすことは昨今珍しくないですし、今後も何が起こるかわからない。そうしたソブリンAIの重要性が高まっている中で、tsuzumi 2をはじめとするAI関連のテクノロジーと、我々NTTグループの強みである公共性の高さやセキュアなネットワーク技術が今後シナジーを発揮していくと見込んでいます。
――専門特化型生成AIを含め、AIエージェントやフィジカルAIなど、これから生成AIを活用したビジネスはどんどん進化し、影響力を高めていくと思われます。生成AIは日本のビジネス環境をどのように変えていくと思われますか?
馬渕氏:冒頭で述べたように、まず自律型のAIエージェントがどんどん進化して、ビジネスの現場に入っていくでしょう。
すでに現場を席巻している例を挙げると、自ら勝手にコードを書いていくAIソフトエンジニアの「Devin」や「Cursor」、「Claude Code」などは本当に衝撃的です。例えばDevinは、コードを自動生成してプロダクトをつくるだけではなく、そのプロダクトのテストやデバッグまでも自律的に判断して実行します。本来必要な「生成されたプロダクトを評価し、修正指示を追加する」という人間の役割をも、Devinが代替してくれるのです。
――いわば、Devinが自らデバッグ担当の“Devin B”をつくって操り、プロダクトの品質を勝手にどんどん高めていく?
馬渕氏:そういうことです。これからの製品開発では、AIエージェントによって品質は指数関数的に向上し、完成までに要する期間も劇的に短縮される。アプリケーションにしろ、プロダクトにしろ、開発のスピードとクオリティが圧倒的に変わってくると思います。
日本はこれまで「失われた30年」「DX後進国」といわれ続けてきました。ですが、これからのAI進化の流れにしっかり追随し、特に日本がグローバルで伸びしろのある領域に注力してアクセラレーションしていけば、取り戻すチャンスは十分あるのではないでしょうか。

――日本の勝ち筋としては、どこにアクセルを踏んでいくべきでしょう。
馬渕氏:日本の産業界に残るレガシーをAIで復権させることでしょうね。例えば製造業。グローバルにおいても、やはり日本のものづくりのすごみは伝わっており、価値がある。しかし今は深刻な少子高齢化で、職人的なものづくりのワザが消えかけています。これこそAIに学習させるべきです。
昨今、事業承継における後継者不足の問題が大きくなっていますが、私は「AIに事業承継してスケールさせる」イメージが重要になってくると思っています。
――単なるAIへの技術移転ではなく、事業承継をする。
馬渕氏:政府も中小企業を積極的に応援しています。優れた技術や知見を持っている企業が多いからです。ただ問題は、優れた技術を活用して、さらにビジネスとしてスケールするような企業が少なくなっていること。そこで、職人的な知見や優れた技術データを自社だけに残すのではなく、専門特化型生成AIとして他社や他業界に横展開するのです。
すると、A社で培われたものづくりの知見がより多くの現場の生産性向上に貢献するだけでなく、異業種への応用による新たなイノベーション創出も期待されます。AIエージェントがそのポテンシャルも踏まえて自律的に稼働し、無限に壁打ちを繰り返しますからね。そのようにビジネスを拡大させていくイメージです。
――なるほど。専門性の高いデータをAIが学習することで、ものづくりの高等技術や知見が標準化され、さらに新しい価値の創出にもつながると。
北川:そのビジネスモデルは、海外にも展開できるかもしれませんね。ものづくり技術はもちろんですが、AIに事業承継させるような形は、日本同様に少子高齢化が進む中国などでも今後ニーズが高まりそうです。
ちなみに、建設などの業界では、まさにそういった試みを進めるスタートアップが日本で動き始めています。各社に残る属人的なノウハウを取りまとめてデータ化し、互いに利活用する協力体制を構築しつつ、データセットをAIに学習させ、SaaSとしても提供する。新たな価値創出にまでつなげたビジネスモデルが革新的です。
このように、技術や知見の伝承に役立てるだけでなく、日本企業の持つ伝統的な価値を標準化して、さらに専門特化型生成AIとして国内外の他社に提供することでトップラインも押し上げていく。そういう流れは日本のみならずグローバルでも期待されていますが、実際に動き出している例はまだそう多くはありません。
先進技術は、成功事例が生まれると一気に普及します。ひとつでも形になって、日本から世界に発信できたら、大きなインパクトとなって潮目が変わるかもしれません。

馬渕氏:確かに、そういった潮目が変わるタイミングは着々と近づいていると感じますね。ほかにも、LLMだけでなくデータを収集するIoT技術、例えば職人のファジーな手作業を画像で解析してデータ化する、といった部分でも、AIが技術の進化を加速させています。今後はロボティクスやヒューマノイドなどの進化と相まって、医療や介護、物流、製造などのあらゆるリアル空間にAIエージェントやフィジカルAIが普及していくでしょう。
――こうした流れに乗るために、一人ひとりのビジネスパーソン、あるいは経営者はどんな意識を持つべきでしょう?
馬渕氏:生成AIを業務効率化にとどまらずに会社の事業内容を進化させるようなアクセラレーターにするためには、とにかく仕事でもプライベートでも「AIを使い倒してみる」ことでしょうね。
私はもう長いことデジタルビジネスの世界にいますが、その中で大きな時代の変化を3つ体感してきました。インターネット、スマホ、そして今の生成AIです。
ネットもスマホも、最初に「使いものにならない」「どうビジネスに活かせるのか見えない」といって触ろうとしない人たちはいつも一定数いました。でも逆に、遊び半分でもどんどん触って、考えて、試してきた人たちは、次々とアイデアを形にしていきました。そして、みな当たり前に使いこなす時代が来たころには、その差がとても大きくなっている。
生成AIもまさに同じ流れにあり、かつネットやスマホより圧倒的な速さで進化しているからこそ、まず触ってみることの重要性は増していると感じます。
北川:同感です。とにかく触って、試して、何ができるかを想像してみる。そこからですね。得てして私たち日本人は真面目すぎるので、新しい挑戦をしようとすると、つい手段が目的化して、袋小路に陥りがちです。
例えば、専門特化型生成AIを自社に活用しよう、といった時に「まずはデータを整理して……」「次にデータをクレンジングして……」「その後、生成AIに学習させて……」とフレームワークで考えすぎる。すると「データをたくさん集めよう」「まだ足りないのではないか」「もっとこんなデータも必要なのではないか」「クレンジングするんだから、先に整理しておいたほうがいいのでは」と几帳面にやりすぎて、なかなか先に進めなかったりします。
まずは「どんなことができるだろう」と大きく未来を思い描いて、バックキャスティングしていく。それこそが何よりも大事だと、実際に多くの企業と関わる中で実感しています。
馬渕氏:自分は、自社は、あるいは日本は、どのような仕事で世界に改めてプレゼンスを発揮していきたいのか。そんなイメージを頭の片隅で育みながら、とにかく生成AIに触っていく。専門特化型生成AIビジネスの種は、どんな日本企業もすでに持っているはずです。生成AIの加速度的な進化を追い風にして、うまく育てていってもらいたいと思います。
北川:我々も、その種を育てるために必要なデータクレンジングや、企業の強みの落とし込みなどをパッケージ化してサポートできるように生成AIビジネスを進化させていきたいですし、さらにグローバルに展開できるような共創を促進して貢献していけたらと思い描いています。


OPEN HUB
THEME
Generative AI: The Game-Changer in Society
#生成AI




