


01
2024.04.20(Sat)
目次
※冒頭にご紹介したセミナーをオンラインで配信しています。ご関心のある方はこちらよりお申し込みください
— 基調講演では、「AIを使いこなさないと、これからビジネスを成立させるのは難しい」という提言がありました。とはいえ、企業としては新規ビジネスやサービスを拡充する「攻め」と、セキュリティやガバナンス、コスト管理などの「守り」のバランスを考えなければなりません。どのような優先度を付け、両立を目指すべきでしょうか。
大野氏:どのようなデータを扱うかという観点から、攻めと守りの両面のリスクを評価する必要があると考えています。すでにインターネットに公開されているような企業データはChatGPTのようなエンタープライズ(企業向け)サービスを使うべきです。スピード、スケーラビリティを最大限に活用した迅速な「攻め」の市場投入ができるでしょう。
一方で社外秘のような機密性の高いデータを扱う際は「守り」の視点から注意が必要です。生成AIサービスの規約の多くには入力されたデータは学習に使わないと明記されていますが、使っていないことを証明するのは困難です。
このようなセキュリティリスクを考慮し、自社の保有するデータの価値に応じて、エンタープライズサービスを使う、ローカルな推論環境を構築するといった使い分けが必要ではないでしょうか。

北川:現時点では「攻め」を優先すべきだと考えています。とくにAIを導入して競争力が上がる分野に関しては、より積極的に活用しなければならない状況です。ただし、「守り」の観点でセキュリティを担保する必要もあるでしょう。
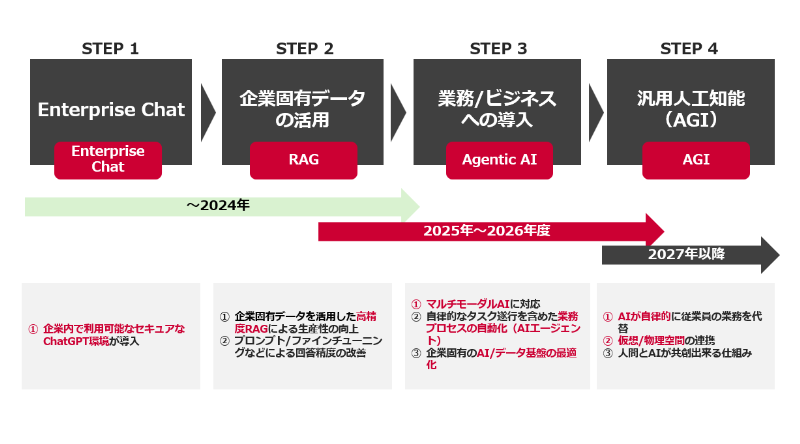
そこで、まずは社内への影響が少ないところから生成AIを安全かつ効率的に活用できるエンタープライズチャットの導入からスタート。徐々に大規模言語モデル(LLM)に検索機能を組み合わせたRAG※で企業固有のデータを活用する、そしてユーザーの代わりにタスクを完了させるAIエージェントを業務に溶け込ませていくといったステップアップがセオリーです。それが結果として「攻め」に重きを置きつつも、企業固有のデータのセキュリティを担保する「守り」にもつながると考えています。
※RAG:検索拡張生成(Retrieval-Augmented Generation)のこと。RAGは学習データに加え、社内文書などの外部データからの検索結果を組み合わせて回答を生成するため、より正確で信頼性の高い最新情報を含む回答が可能となる
正岡:私は「守り」、つまりセキュリティとガバナンスを優先すべきだと思います。データの保護、アクセス制御、脅威検出など、包括的なセキュリティ対策をすることで、はじめて「攻め」の取り組みを安心して進められるようになるためです。
次に、優先すべきはコストの最適化です。新規ビジネスやサービス拡充に対する投資効果を評価して、効率的なリソース利用を含めてコスト対効果の高い取り組みを優先させる見極めが重要になります。
そして最後が社内関係部門の連携強化です。事業部門、情報システム部門、セキュリティ部門などの関係部門が協力して共通の目標を決める。その上で目標に向かって取り組みを進めることで、バランスの取れたAIインフラの導入および継続的かつ効果的な活用が実現できると思っています。

— AIの運用では、パブリッククラウドと専有型ICTインフラ(プライベートクラウドやオンプレミスによるICT環境)を組み合わせたハイブリッド環境の重要性が指摘されています。導入を進める上で企業が陥りがちな失敗、注意点を教えてください。
大野氏:ハイブリッド環境を立てる際にはパブリッククラウドと専有型ICTインフラ、それぞれの強みと弱みを正確に理解しないと投資効果は得られません。パブリッククラウドが持つリソースの拡張性は非常に魅力的です。一方でGPUリソースは非常に人気が高いため、大規模なGPUクラスタをパブリッククラウドで活用する場合には、いくらお金を積んでも借りられない事態が起こりえます。このため、大規模なリソースを安定的に確保する際には専有型ICTインフラを利用するという選択肢もあるでしょう。ただし、もちろん初期投資や固定費はパブリッククラウドに比べて負担が大きくなります。
そのため、どれくらいの期間、どれくらいの計算リソースを確保する必要があるといったリソースの需要計画を立て、その計画に基づいて導入判断することが重要になると思います。
北川:私の経験上、オンプレミス環境の専有型ICTインフラを活用するにはいくつかの課題があります。もともと、生成AI運用のユースケースの多くがクラウドベースのため、パブリッククラウドのパーツに頼った設計になっています。いざ、専有型ICTインフラに生成AIを実装しようとすると、これが足りない、ここがうまくいかないといった問題が少なくない頻度で発生します。

さらに専有型ICTインフラを利用する際には、併せてクローズドな環境で利用できる専有型LLMを使いたい要望も多くいただきます。しかし、ChatGPTやGeminiを使い慣れている人からすると、性能的に物足りないと言われることもよくありますね。
もう1つ、企業の保有するデータがそのままLLMに利用できるケースは多くありません。構造化などの準備に想定外のコストがかかることもあります。ハイブリッド環境に限ったことではないのですが、よく私が導入の現場で直面する問題です。
正岡:確かに、ハイブリッド環境の導入には初期投資だけでなく、運用コストや、クラウドからオンプレミスへのデータ移行、高度なセキュリティ対策などの追加コストも発生する可能性も高いので、想定外のコスト増に向けた予算の確保は必要ですね。
— 「PoC止まりで終わってしまうプロジェクトが多く、成功率が非常に低い」という話が基調講演でありました。実際に現場が使い続けるAIツールを根付かせるために有効な方法はどのようなものでしょうか。
正岡:まず、明確なビジョンと目的を設定して全社的で共有、組織全体の理解と協力を得ることです。次に、現場の意見に耳を傾け、業務プロセス・課題を深く理解した上で現場のニーズを反映したユースケースをつくることです。さらに、小規模なプロジェクトからスタートして成功事例を積み上げ、リスクを最小限に抑えつつ他部門へ展開していく段階的な導入とスケールアップも欠かせません。
また定着のためには、導入されたAIツールの有効活用に向けた継続的な研修やサポート体制の準備も重要です。そしてAI導入の具体的な成果を定量的に評価・可視化し、組織全体にAIの効果を実感させるとともに、現場からのフィードバックを基に改善を継続することも必要でしょう。これらのポイントを押さえることで、PoCで終わらず、現場にAIツールを根付かせ、企業の持続可能な成長に繋がると考えます。
北川:AIの実装では、すぐに期待通りの精度が出るわけではありません。利用する事業部門には最初は精度が出ないことを許容して、いつか良くなると信じて使い続ける根気が必要です。一方で構築側の技術部門は、精度を高めるために最大限の努力をする必要があります。
RAGベースで話をしますと、たとえば、しっかりデータを構造化して整備する、チャンク※を調整するなどです。正岡からもありましたが、なにをやっているのかわからない袋小路にならないよう、全社的に目的とユースケースを共通見解として持つことが大切なのかなと思います。
※チャンク:データを意味のある小さな単位やかたまりに分割したもの。これを調整することで、検索や分析が効率的に行えるようになる
大野氏:AIを組織に根付かせるためには、その企業特有のドメイン知識が必須になります。個々の企業が持つ顧客やその対応方法、進行中のプロジェクトの注意点、過去の成功・失敗事例といった固有のデータを理解した上で、日々の業務をサポートする仕組みでなければ現場では徐々に使われなくなっていくでしょう。AIを根付かせるためには、自席の近くにいる詳しい人に聞くよりも、かんたんに有効な情報や示唆が得られなければなりません。
AI時代において、いちばん重要な企業資産はデータです。社内のデータを集めてきてOCR※などでデジタル化、LLMが読み込めるかたちに変換する。業務理解とデータがセットになって初めて企業で活きるAIがつくれるようになると思います。
※OCR:光学式文字認識(Optical Character Recognition/Reader)のこと。紙などに書かれたテキストを画像化して読み取り、デジタルデータに変換する技術

— 生成AIに特化したセキュリティリスクに必要な新たな対策はありますか。
北川:たとえば、AIに悪意のある指示(プロンプト)を入力して本来の機能から逸脱した結果を引き出す攻撃手法であるプロンプトインジェクションの対策としては、悪意ある入力のクリーンアップが有効です。最近、NTT Comでも入出力テキストの安全性を判定する「chakoshi」をリリースしましたが、このようなツールを導入して、万一変なプロンプトが入ってきたとしてもブロックして、答えない対策を行うことが重要です。加えて、RAGにおけるファイルのアップロードなどをフィルターする仕組みも必要になってくると思います。
— 今後AIエージェント同士がやりとりするケースも増えると予想されますが、セキュリティ・ネットワーク面で注意すべきことや将来的な課題にはどのようなものがあるのでしょうか。
北川:AIエージェント同士の会話はAPI連携で行われるため、最初の認証をしっかり行う必要があります。たとえば、ゼロトラストに基づいて、社内外どこからアクセスする場合でも、多要素認証を行う仕組みを導入すれば安全性が高まります。また、AI同士がデータをやり取りする際は、どれくらいのデータを処理しているのか、サーバーが重くなっていないかなどを常に見張っておくことが重要です。当然ながらデータの暗号化も必要になると思います。
— GPUクラスタの構築で気をつけるべきポイントはありますか。
大野氏:GPUサーバーを買ってきたらすぐにスタートできると思われる方が多いのですが、そうではありません。データセンターにインフラをつくる、ネットワークを引いてセキュリティを強化する、GPUサーバー同士を接続する、インターコネクトをセットアップするといった、多岐にわたる技術が求められます。これらのコストパフォーマンスを最大化して、総合的な構築を行うにはエンジニアスキルの総動員が必要です。このため、私たちはGPUクラスタの設計・構築を、技術の総合格闘技と呼んでいます。
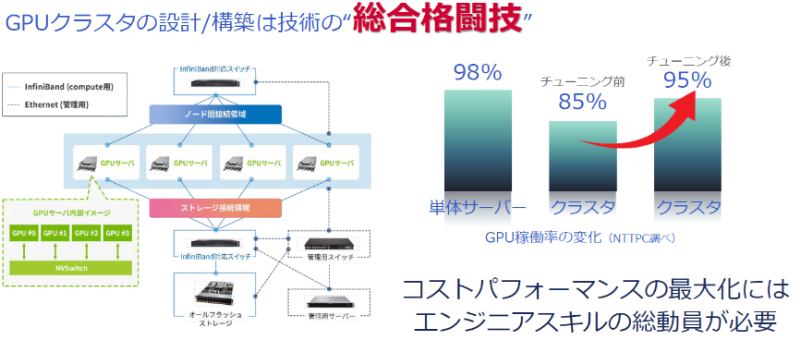
大野氏:これらを踏まえた上で、大きな電力を消費するGPUクラスタ構築のポイントとなるのは、まず電力に余裕のあるデータセンターを確保することです。さらにデータセンターの選定ではサーバーの冷却方式も確認しておきましょう。一般的な空冷に比べ、水冷、液冷の冷却方式を採用しているセンターの方が高発熱のGPUクラスタのパフォーマンスは上がりますし、故障率が下がるデータがあります。
— データセンターの選定にもコストだけでなく環境面の配慮を含めた基準が求められる中、今後のサステナビリティ対応で特徴的な取り組みはありますか。
正岡:当社が提供する「Green Nexcenter®」は、環境に配慮したデータセンターとして、特長的な取り組みを行っています。まず、液冷方式の採用により従来の空冷方式に比べて冷却効率を大幅に向上させています。これにより、生成AIやGPUなどの高発熱サーバー機器の冷却に必要な消費電力を約30%削減できます。
さらに自社設備にかかる電力に100%の再生可能エネルギーを利用するとともに、センターをご利用のお客さまにも同様の再生可能エネルギーを提供し、CO2排出量を実質ゼロにする取り組みを進めています。
また、国内最高レベルの電力使用効率を実現しており、提供ルーム単位の電力使用効率pPUE1.15というすぐれた数値を実現しています。これにより、データセンター全体のエネルギー効率を向上、運用コストの削減にも寄与します。今後も地球温暖化の原因となる温室効果ガスの排出を抑制するサステナビリティ対応を継続して強化していく計画です。
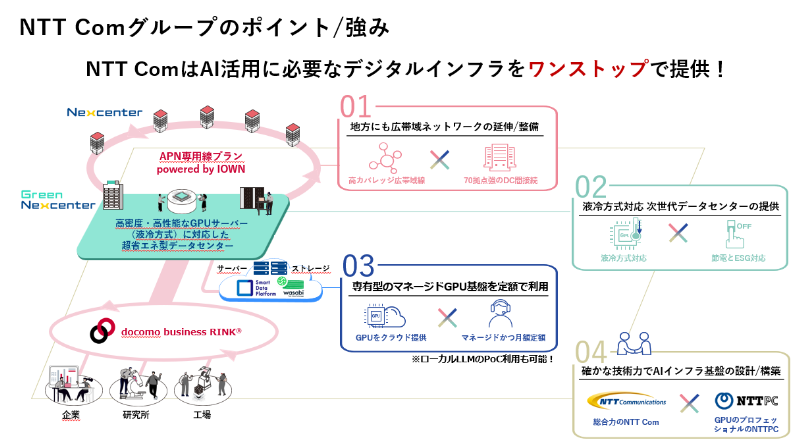
正岡:今後、日本企業においても独自データを使った自社専用のAIのためのデジタルインフラを構築する機会は増えてくるでしょう。NTT Comでは液冷方式サーバー対応のデータセンターの「Green Nexcenter®」の提供に加え、専有型のGPUサーバーをネットワーク・ストレージ込みの月額料金で提供できるマネージドサービスから、国内70拠点以上のデータセンターを接続する広帯域ネットワーク、そして蓄積したノウハウや実績を活かしたお客さまに最適なデジタルインフラ基盤の設計・構築まで、幅広いサービスをご用意しています。AIインフラの構築を検討中であれば、お気軽にご相談ください。
ビジネスにおけるAIの活用が進むなか、その基盤となるAIインフラの整備は企業競争力を左右するポイントの一つになりつつあります。時としてインフラというとコストセンターと見なされるケースもありますが、適切なAIインフラの構築は、効率化はもちろん、新たなサービスや価値の創出へとつながっていくはずです。

OPEN HUB
THEME
New Technologies
#最新技術




