

01
2024.04.20(Sat)
この記事の要約
NTT Comの社内DXでは、生成AIの活用が業務改善に大きな影響を与えています。
導入プロセスでは、ガイドライン策定から始まり、個人利用からチーム間利用へと拡大。
セキュアな環境で生成AIアプリケーションを活用できる環境構築や、社内のニーズに応じた活用が進められています。
また、生成AIが業務効率化だけでなく、精神的なサポートも提供する可能性が模索されており、ビジネス変革に期待が寄せられます。
※この要約はChatGPTで作成しました。
目次
――NTT ComでのDX戦略の立案と実行をリードする二人が担っている業務について教えてください。
西塚要(以下、西塚):私が所属するデジ改のデータドリブンマネジメント部門は、データ活用、データ集約やシステム連携の指揮をとるセクションです。
一言でデータといっても多岐にわたりますが、サイロ化した社内およびグループ間のあらゆるデータを一気通貫してデータベース化することで、さまざまなインサイトを得ることが可能になります。こうした定量的な判断材料に基づいて、データドリブン経営の推進をはじめとした、各部署の業務改革を行っています。
NTTグループ全体の取り組みとして、グループ内115社に存在するITシステムを共通化した大規模バックオフィスシステムの構築を図っているのですが、NTT Comでは2023年4月に先行して導入しました。ここにあてはまらない社内データについても独自に基盤を整えています。
こうした社内のDX推進と同時に、そこから得たノウハウと知見をお客さまにソリューションとして提供し、社会にインパクトを与えていくのも私たちのミッションです。会社全体でのデータサイエンティストの育成にもチームとして携わっています。

沢田裕太(以下、沢田):同部のDX戦略部門では、全社のDXをどのように進めていくか、方針を策定し推進しています。中でも私はより現場に特化した業務改善を多く手がけています。
社内では各部署が営業、サービスなど、それぞれにミッションを持っていますが、目の前の業務プロセスの改善を専門としているわけではありません。そこでわれわれのチームが課題の棚卸しからソリューションの導入まで伴走します。モデルケースが生まれたら、同じような課題を抱える別組織にも展開し、社内全体の業務標準化を図っています。
西塚のデータ活用の話にひもづけると、部署ごとに属人化された情報が紙やエクセルを使ってアナログ管理されていた時代もありましたが、現在は人手に頼らず、適切なデータ処理を促すための自動化を社内横断型で行い、データベースが整合性を担保したキレイな状態に整っています。これは、有益なインサイトを抽出するためにも重要なプロセスです。

――いわば「DXの成功例」をバックエンドとフロントエンドで連携しながら、実証実験から積み重ねているのですね。今回の生成AIプロジェクトはなぜ立ち上がったのでしょうか?
西塚:DX分野において生成AIの活用は欠かせません。社内における生成AIを活用した業務改善と、お客さまへのソリューション提供の2つの試みが、両輪となって相互に機能していくことを目的として本プロジェクトが立ち上がりました。
沢田:しかし、業界全体として「生成AIでなんでもできる!」といった雰囲気が先行したことで、いざ生成AIを使ってみたものの、どうしたらいいのかわからない、想定した結果が得られない、といった声が社内外から多く聞かれました。
こうしたギャップに惑わされないために大切なのは、活用の過程に目を向けることです。検証方法の共有やユースケースのアップデート方法まで、この一連のプロセスからノウハウが集約され、お客さまに提案できるソリューションが生まれてくると感じています。
――社員全員の生成AI利用から着手したとのことですが、実際にどのように環境を整備していったのでしょうか?
西塚:まずはガイドラインの策定からです。生成AIを業務で使いたいという声がたくさん上がってきたときに、安全な利用を促す基準をつくりました。
セキュリティ上使ってもよい生成AIサービス、機密度に応じて取り扱える社内データの種類など、推奨・禁止の線引きを明確にしました。実際に使用したサービスはデータを回答以外に活用しないもの、つまり再学習に使用しないとうたっているもののみです。
とはいえ禁止事項ばかりが増えてしまうと、ガイドラインから外れて私的に利用する“シャドーAI”の温床にもなりかねません。あらゆる情報漏えいのリスクを避けながら「どうすれば正しく使えるか」という考え方をベースに定めていったのがこのガイドラインです。

沢田:実際にガイドラインに沿って個人利用を促していく上では、ノウハウをこちらから伝えていくと同時に、利用者(社員)側からも回答の精度を上げるための実験を重ねていくよう働きかけることがポイントになります。
というのも、生成AIがこれまでのITシステムと大きく違うのは、成功と失敗の判断がつきにくい、すなわちバグがわかりにくいという点です。たとえおかしな回答が返ってきても、回答がある時点でそれはシステムとしては正しい挙動であり、「精度が期待に沿っていない」ということを読み解く必要があります。生成AIは完全なツールではないので、教育していくことで精度が上がるという気づきを得てもらうところがスタートです。
西塚:また、使ってみて良かった/悪かったという感覚論ではなく、どういった回答が得られたら業務活用できるかの基準を明確に定める必要もあります。今後は具体的な改善事例を集めて、結果の数値化とノウハウを集約するフィードバックの仕組みも構築していく予定です。
――現在はチーム間利用にも着手されているそうですね。社内DXで生成AIを活用する事例はまだそう多くはないと思いますが、こうした取り組みを可能にした技術についてお聞かせいただけますか。
西塚:まずは広く社内利用としてNTTドコモグループが2023年8月に発表した「LLM付加価値基盤」という独自のプラットフォームを活用しています。
この基盤はAzure Open AI Serviceなどのオープンソースの「LLM(大規模言語モデル)」、あるいは NTTが独自に開発した日本語の大規模言語モデル「tsuzumi」などとAPI連携しています。精度の高さは出しつつも、投げ込む機微なデータが外部に漏えいしないようセキュアなフィルタリング機能が実装されています。
このLLM付加価値基盤に加えて、チームとして業務改善に使える生成AIアプリケーションを提供して社内で活用していこうというのが今回の社内実験です。
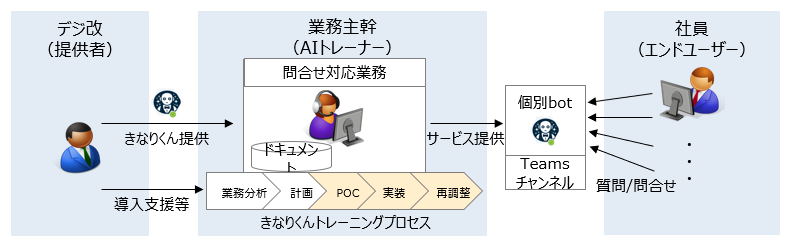
沢田:実際に社内で希望を募って生成AIアプリケーションを活用してもらっています。それこそ営業からバックオフィスまで多岐にわたったチームが実証している最中ですね。
解決したい課題であり、かつ生成AIのポテンシャルが発揮できる領域の1つが「サービス仕様・業務マニュアル」に関する応答です。お客さまや取引先、あるいは他部署や新人社員からのサービス仕様に関する問い合わせは、社内に飛び交うものです。これまでは業務担当者にメールやチャットが直接飛んで、一つひとつ答えていく必要がありました。ただ、そうした問い合わせの答えの約8割が「マニュアルに書いてあること」なんですね。こうした悩みは私たちのみならず他企業でもよくある課題です。
アプリケーション導入の成果も出始めていて「チャットボットで完結できるようになった」「問い合わせ対応の文章の素案を生成AIで出力でき、大幅な時間短縮になった」との声が上がっています。
西塚:一番ニーズがあったユースケースは、こうした「問い合わせへの回答」でしたが、社内に提供しているのはそれだけでなく、コード生成や会議資料を過去の資料からテンプレート作成する社内文書作成支援など、営業から開発まで部門を拡大して生成AIを活用しています。
――こうしてユースケースを積み上げていくことで知見が蓄えられ、生成AIによる機械学習も積み重なっていくということでしょうか?
沢田:実は生成AIの「学習」を社内利用のケースにおいて行うことはまれです。社内データを学習使用させてしまうと社外の誰かの問い合わせに対して、社内情報を使った回答がされてしまうなど情報漏えいのリスクがあります。生成AIに学習させることなく、回答の精度を上げていく。そのためのノウハウを社内で積み上げていこうというのが今回の取り組みです。むしろ「LLMが学習されないセキュアな環境で、回答の精度を上げられる仕組みをつくった」ことに価値があるのです。
今後は「プロンプトを書くときどのようにすれば精度が上がるか」「セキュリティを保つためには何をしたらいけないか」「気軽に使ってもらうためにはどんな声がけが必要か」といったプロセスを積み上げて、活用の解像度をさらに上げようとしているところです。そうしたノウハウも含めて、お客さまに提案するときの磨き上げになっています。

西塚:お客さまへのソリューションの幅を広げていくという意味で、システム的に取り組めることはまだまだあります。
企業の中の生成AI利用の3つのステップとして、まず1つめはChatGPTに代表される生成AIを実際に個人が使ってみる。次に2つめとして社内ドキュメントをふまえた活用があります。それが今回の社内データをもとに、RAGという手法で回答を導き出すというものです。NTT版LLM「tsuzumi」のように、アダプティブチューニングといって特定の分野に特化した内容を追加で学習するようなアプローチをとる場合もあります。
さらに3つめは、社外のお客さまの問い合わせに対して生成AIで回答するなど、お客さま向けのサービスに生成AIを活用していくというものです。ここまでいくとさらにきめ細やかなチューニングが必要となるため、かなりの精度目標や倫理問題などを突破しなければなりませんが、最終的にはそのフェーズを目指していけたらと考えています。
――ビジネス活用に取り組む中で、生成AIがもたらす可能性の広がりはほかの視点からも見えてきましたか?
沢田:一般に生成AIは人が持つ力を拡張したり、苦手な仕事を代替してくれる可能性を持っています。それは時間やコストの削減だけではなく、精神的ストレスの削減にも作用して、そこに生成AIがもたらす意義があると思っています。
西塚:同感ですね。社内でも生成AIを「すぐにでも使いたい」と声が多く上がるのは、お客さまからの問い合わせやクレームをいただく部署が多いです。お客さまの意見は真摯に受け止めなくてはなりませんが、対応するのが人間である以上、ストレスを感じないということはありません。
しかし、生成AIが事前にフィルタリングして、不要なネガティブ表現を取り除いたり、問い合わせ内容を要約して伝えたりするようになれば、ストレスは大きく改善できると思うのです。

――今後のビジネス変革に向けた期待はありますか?
沢田:多くの仕事を効率化し、質を高めるのは間違いありません。それと同時に、いまお話ししたような精神的なサポートにつながることも見えてきたので、生成AIが人に活気を与えるという側面からも発展性が期待されます。
西塚:業務改善のみならず働き方のアップデートや新しいサービスの誕生に期待しますね。プロジェクトに参画しているメンバーをみても、若い人ほど積極的に生成AIを活用する機運があるように思います。若手を中心とした新たな価値観とアプローチで業界が活性化され、3年後には働き方やビジネスそのものが様変わりしているかもしれません。そんな未来がすぐそこまで来ていると感じていて、NTT Comとしても、その一翼を担えたらと思っています。
関連記事:「生成AIとは?主なサービスとメリット・課題点、利用時のガイドライン」

OPEN HUB
THEME
Generative AI: The Game-Changer in Society
#生成AI




